
Your LLM doesn’t know what your data means
Read this if you're building AI products for structured data

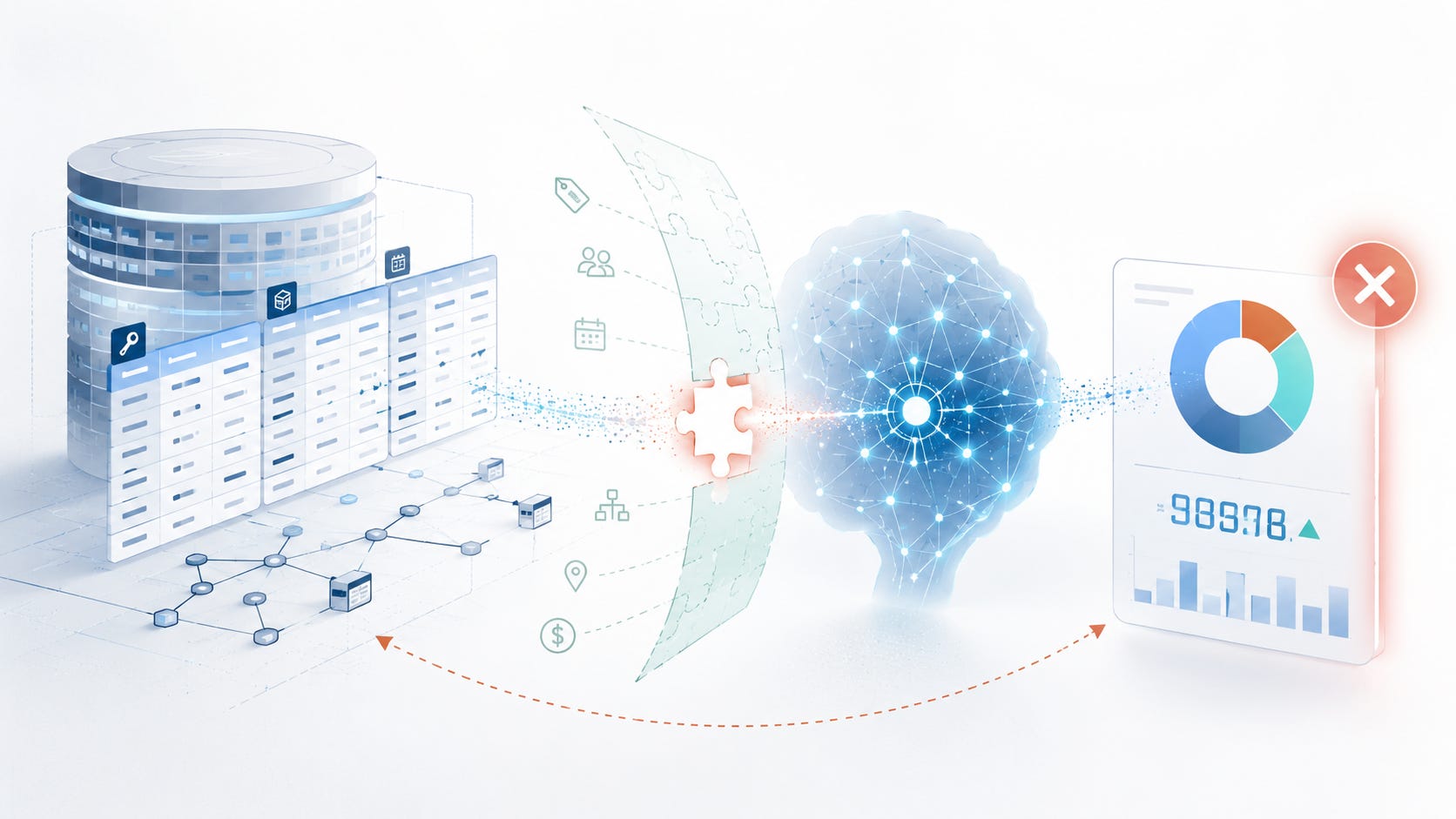
For those involved in building data agents, here’s a common situation: You wired language models into your data warehouse. The schema’s in the prompt, the demo went well. Then someone asks “what was refund volume in Q3?” and the bot confidently sums orders.amount where status = 3, because 3 sounded like cancelled sounded like refund. None of it is true. The query runs, but the number is wrong.
Snowflake and Databricks both ship AI-generated cataloging features , and they help, but they stop at one-line column descriptions inferred from names and types. They don’t know your region = 'XX' is the test tenant, or that one row in orders is actually a line item.
Schemas describe shape, but what your bot really needs is meaning.
The fix isn’t a better prompt: it’s a metadata catalog
What’s missing from your bot’s view of the data is what every analyst on your team picks up in their first week:
Grain is one row in
ordersan order, a line item, or a daily snapshot?Semantics:
amount < 0is a refund.region = 'XX'is the test tenant.status = 3means returned, not cancelled.Relationships which keys join cleanly, which point at deprecated tables.
Quality:
customer_emailis 30% null;created_athas a gap from a 2023 migration.
None of this is in the schema. Stuffing more CREATE TABLE into the prompt doesn’t help, since the information was never there to begin with.
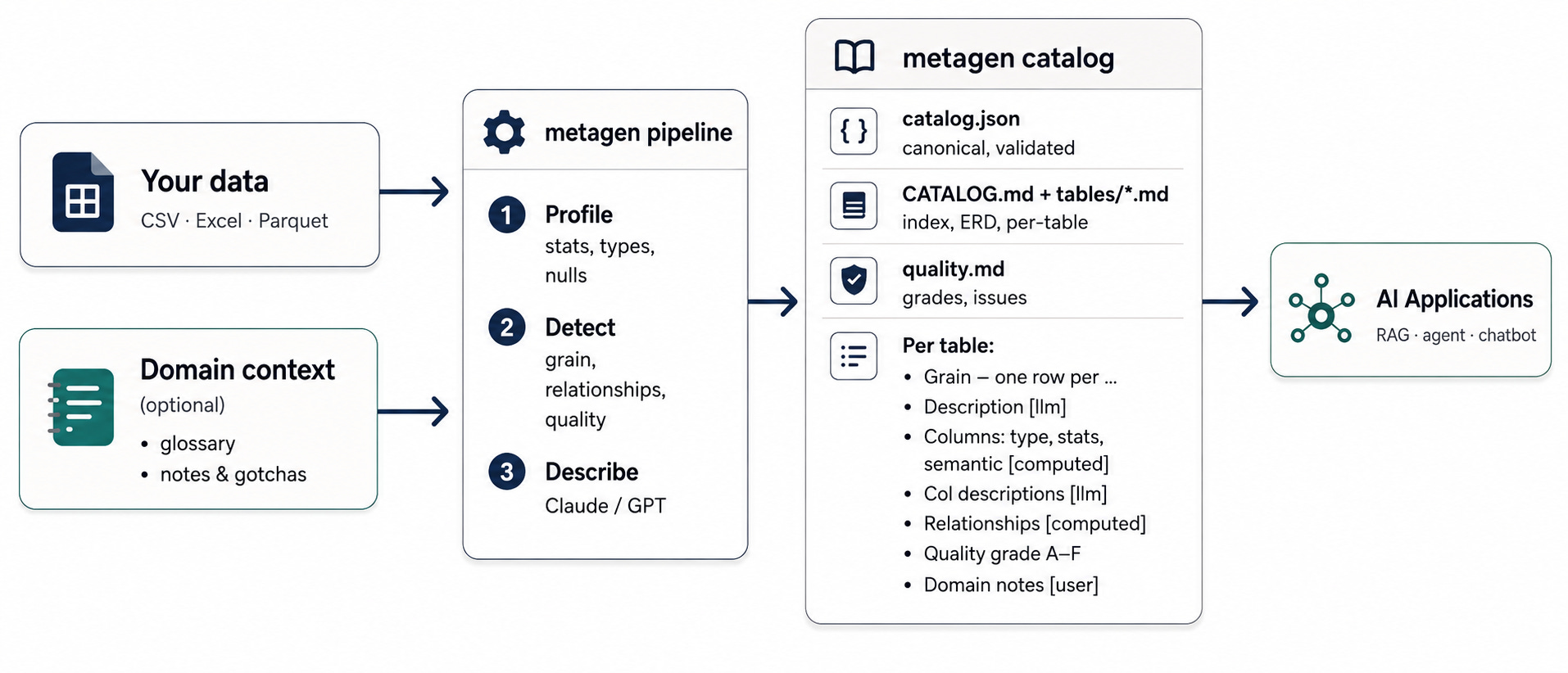
The pattern that works is the one every serious GenAI rollout converges on: pre-compute the context. Profile the data once, generate a metadata catalog: computed stats, LLM-written descriptions, your own domain notes; and feed that to the bot as context. Suddenly the model knows what status = 3 means, because someone wrote it down, once, in a place the model can read.
metagen: the catalog in one command
metagen is an open-source TUI that I built that does exactly this for any CSV, Excel, or Parquet dataset on your machine:
Point it at a file or folder
It profiles every column (nulls, distincts, ranges), detects each table’s grain, infers relationships, and writes plain-English descriptions via Claude or GPT
You can type in your own domain context, for eg. “
status = 3is returned, ignore region XX”, and it flows directly into the LLM promptsOutput is JSON (machine-readable, schema-validated) and Markdown (human-readable, GitHub-friendly), with every claim source-tagged
You can find the repo here: https://github.com/voralabs/metagen
Clone it and test it in seconds without any custom setup required. You will need to add your own LLM API keys for this.
Roadmap
Today metagen works on local files. Next is:
Connectors for Snowflake, BigQuery, and Postgres
OSI Output format (OSI stands for Open Semantic Interchange - launched by Snowflake last year)
Composite key profiling
Agentic definition (perform model assisted queries to deeply understand the data similar to how a data scientist/analyst would do)
The point is that the catalog is the unit of context engineering for any LLM that touches structured data. And building one shouldn’t take a quarter. If you’re wiring an agent to your warehouse right now, generate the catalog first. Review and enhance it if needed. Hand the model the meaning.
Repo: github.com/voralabs/metagen. Issues and PRs welcome.
Great work! Keep building and sharing
I appreciate the insights you regularly share to make AI easy to understand for all especially for non technical users. Keep it up!